Flink中的时间
流处理与批处理
流处理可以想象成有一条水流,只不过这条流里面流动的不是水而是数据。以京东统计销售额为例,想知道618当天的销售额是多少,有两种实现方法:
批处理:在618当天结束的时候,统一进行分析处理,大概就是一个select sum(amount) from trade。用水流的例子,可以把水流的水(数据)都集中在一个大水箱里面,然后在某一时刻分析水(数据)的情况,但是这样的分析并不是实时的,只有当天结束的时候我们才能看到统计的数据。
流处理:交易数据是源源不断的,一个接一个来,比如在00点00分01秒来了一个手机下单的交易数据,在00点00分02秒来了一个电视下单的交易数据,这些数据一个个来到,越积越多,我们迅速处理这些信息,没有延迟。就像在溪流的某个地方设立一个检测仪,检测水(数据)的实时情况,这样我们可以实时地看到统计数据。
窗口
在上面这个场景中,我们需要面对的是连续不断、无休无止的无界流,但是我们只关心一段时间内数据的统计结果(618 00:00:00~618 23:59:59),在这种情况下,我们就可以定义一个窗口,收集最近618当天所有交易数据,然后进行统计,最终输出一个结果。
在 Flink 中, 窗口就是用来处理无界流的核心。可以把窗口想象成一个固定位置的“框”,数据源源不断地流过来,到某个时间点窗口该关闭了,就停止收集数据、触发计算并输出结果。
例如,我们定义一个时间窗口,每10秒统计一次数据,那么就相当于把窗口放在那里:
- 从 0 秒开始收集数据;
- 到 10 秒时,处理当前窗口内所有数据,输出一个结果,然后清空窗口继续收集数据;
- 到 20 秒时,再对窗口内所有数据进行计算处理,输出结果;
- 依次类推;
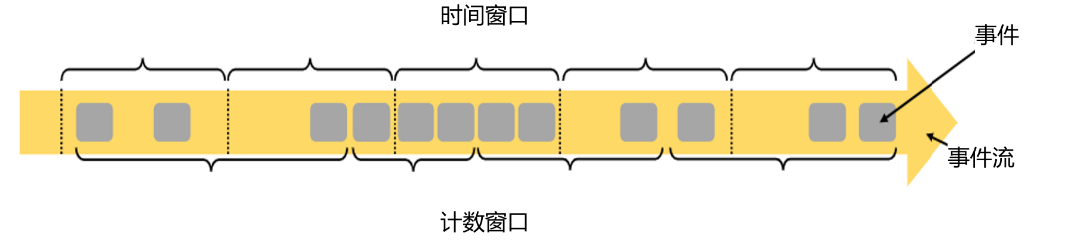
所谓的“窗口”,就是划定的一段时间范围;对在这范围内的数据进行处理,就是所谓的窗口计算。
窗口和时间往往是分不开的。
Flink 中的时间语义
如果我们想要划定窗口来收集数据,一般就需要基于时间。对于批处理来说,因为数据都收集好了,想怎么划分窗口都可以;而对于流处理来说,如果想处理更加实时,就必须对时间有更加精细的控制。
在我们的认知里,只要有一个足够精确的表就可以告诉我们准确的时间了,在计算机系统里,对于一台机器而言,“时间”就是指系统时间。
System.currentTimeMillis()
但 Flink 是一个分布式处理系统,分布式架构最大的特点,就是节点彼此独立、互不影响,这带来了更高的吞吐量和容错性的同时,也会带来时间上的误差:
在分布式系统中,节点“各自为政”,是没有统一时钟的,数据和控制信息都通过网络进行传输。
比如现在有一个任务是窗口聚合,我们希望将每个小时的数据收集起来进行统计处理。而对于并行的窗口子任务,它们所在节点不同,系统时间也会有差异;当我们希望统计 8 点~9 点的数据时,对并行任务来说其实并不是“同时”的,收集到的数据也会有误差。
无法由 JobManager 来协调,因为网络传输会有延迟,且这延迟是不确定的,JobManager 发出的同步信号无法同时到达所有节点;
想要拥有一个全局统一的时钟,在分布式系统里是做不到的。
另一个麻烦的问题是,在流式处理的过程中,数据是在不同的节点间不停流动的,这同样也会有网络传输的延迟。这样一来,当上下游任务需要跨节点传输数据时,它们对于“时间”的理解也会有所不同。
例如,上游任务在 8 点 59 分 59 秒发出一条数据,到下游要做窗口计算时已经是 9 点零 1 秒了,那这条数据到底该不该被收到 8 点~9 点的窗口呢?
所以,当我们希望对数据按照时间窗口来进行收集计算时,“时间”到底以谁为标准就非常重要了。

两种时间语义
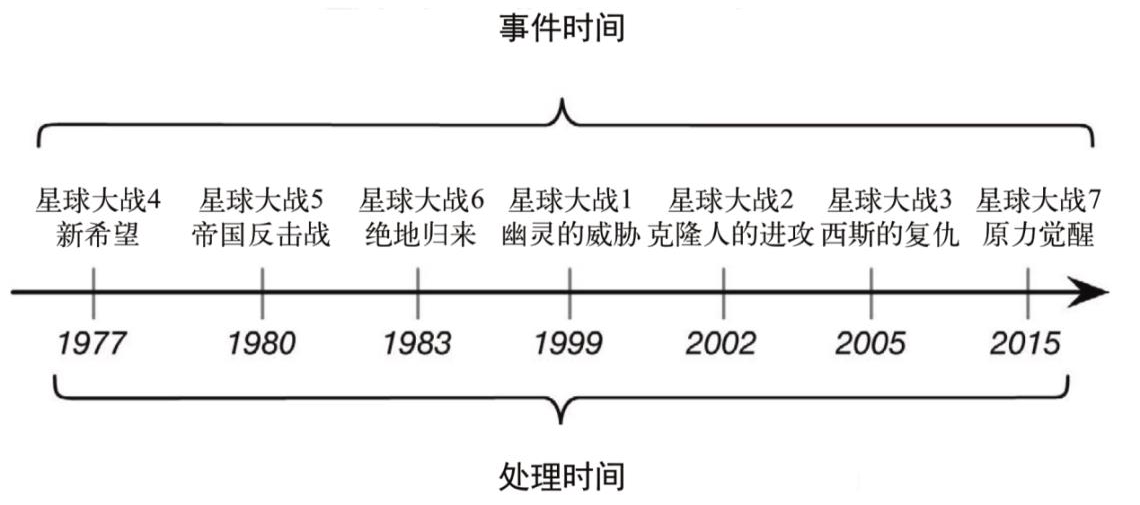
上面的图片中,在事件发生之后,生成的数据被收集起来,首先进入分布式消息队列,然后被 Flink 系统中的 Source 算子读取消费,进而向下游的转换算子(窗口算子)传递,最终由窗口算子进行计算处理。
很明显,这里有两个非常重要的时间点:
事件时间(Event Time):一个是数据产生的时间
处理时间(Processing Time):另一个是数据真正被处理的时刻
我们所定义的窗口操作,到底是以那种时间作为衡量标准,就是所谓的“时间语义”(Notionsof Time)。
由于分布式系统中网络传输的延迟和时钟漂移,处理时间相对事件发生的时间会有所滞后。
处理时间:
处理时间的概念非常简单,就是指执行处理操作的机器的系统时间。
如果我们以它作为衡量标准,那么数据属于哪个窗口就很明显了:只看窗口任务处理这条数据时,当前的系统时间。
这种方法非常简单粗暴,不需要各个节点之间进行协调同步,也不需要考虑数据在流中的位置,简单来说就是“我的地盘听我的”。所以处理时间是最简单的时间语义。
事件时间:
事件时间,是指每个事件在对应的设备上发生的时间,也就是数据生成的时间。
在事件时间语义下,我们对于时间的衡量,就不看任何机器的系统时间了,而是依赖于数据本身。
相当于任务处理的时候自己本身是没有时钟的,所以只好来一个数据就问一下“现在几点了;
由于流处理中数据是源源不断产生的,一般来说,先产生的数据也会先被处理,所以当任务不停地接到数据时,它们的时间戳也基本上是不断增长的,就可以代表时间的推进。
数据一旦产生,这个时间自然就确定了,所以它可以作为一个属性嵌入到数据中。这其实就是这条数据记录的“时间戳”(Timestamp)。
当然,这里有个前提,就是“先产生的数据先被处理”,这要求我们可以保证数据到达的顺序。
但是由于分布式系统中网络传输延迟的不确定性,实际应用中我们要面对的数据流往往是乱序的。在这种情况下,就不能简单地把数据自带的时间戳当作时钟了,而需要用另外的标志来表示事件时间进展,在 Flink 中把它叫作事件时间的“水位线”(Watermarks)。
哪种时间语义更重要
看电影其实就是处理影片中数据的过程,所以影片的上映时间就相当于“处理时间”
而影片的数据就是所描述的故事,它所发生的背景时间就相当于“事件时间”
选择哪种观影顺序?
剧情党?
特效党?
两种时间语义都有各自的用途,适用于不同的场景。
处理时间:
由于网络延迟,导致数据到达各个算子任务的时间有快有慢,对于窗口操作就可能收集不到正确的数据了,数据处理的顺序也会被打乱。这就会影响到计结果的正确性。
这种方式可以让我们的流处理延迟降到最低,效率达到最高,一般用在对实时性要求极高、而对计算准确性要求不太高的场景。
事件时间:
水位线成为了时钟,可以统一控制时间的进度。这就保证了总可以将数据划分到正确的窗口中,但我们知道数据还可能是乱序的,要想让窗口正确地收集到所有数据,就必须等这些错乱的数据都到齐,这就需要一定的等待时间。
事件时间语义是以一定延迟为代价,换来了处理结果的正确性。
由于网络延迟一般只有毫秒级,所以即使是事件时间语义,同样可以完成低延迟实时流处理的任务。
在 Flink 中,由于处理时间比较简单,早期版本默认的时间语义是处理时间;而考虑到事件时间在实际应用中更为广泛,从 1.12 版本开始,Flink 已经将事件时间作为了默认的时间语义。
水位线(Watermark)
事件时间和窗口的关系
举个例子:将生产线上生产的商品,发车运送,要求每个小时生产的商品对应一个车次,一辆车就只装载 1 小时内生产出的所有商品,货到齐了就发车。
怎么明确货物所属的车次(明确数据所属的窗口)?
事件时间是一个数据产生的时刻,就是流处理中事件触发的时间点,一般都会以时间戳的形式作为一个字段记录在数据里。如果我们想要统计一段时间内的数据,需要划分时间窗口,这时只要判断一下时间戳就可以知道数据属于哪个窗口了。
司机什么时候发车(等待窗口中的数据到齐)?
窗口处理的是有界数据,我们需要等窗口的数据都到齐了,才能计算出最终的统计结果。那什么时候数据就都到齐了呢?对于时间窗口来说这很明显:到了窗口的结束时间,自然就应该收集到了所有数据,就可以触发计算输出结果了。
怎么确定这个批次的货物都到齐了(时间的确定)?
处理时间:以当前任务所在节点的系统时间为准
事件时间:以数据中携带的时间戳为准
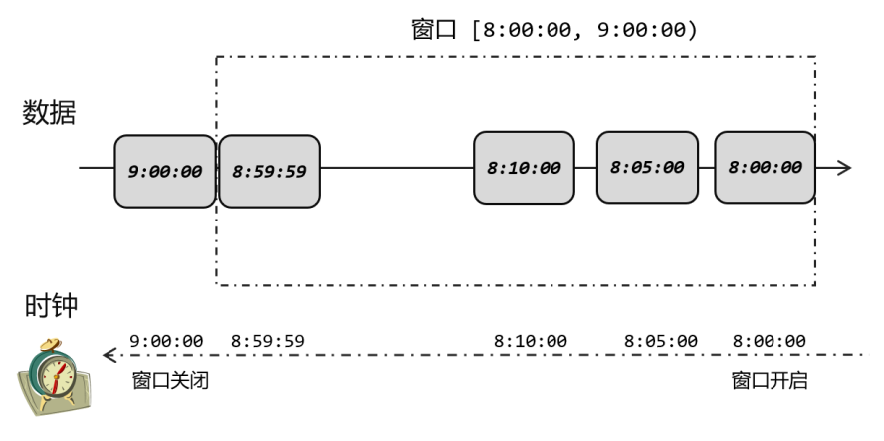
在这个处理过程中,我们其实是基于数据的时间戳,自定义了一个“逻辑时钟”。这个时钟的时间不会自动流逝;它的时间进展,就是靠着新到数据的时间戳来推动的。这样的好处在于,计算的过程可以完全不依赖处理时间(系统时间),不论什么时候进行统计处理,得到的结果都是正确的。
比如 618 的时候系统处理压力大,可能会把大量数据缓存在 Kafka 中;过了高峰时段之后再读取出来,在几秒之内就可以处理完几个小时甚至几天的数据,而且依然可以按照数据产生的时间段进行统计,所有窗口都能收集到正确的数据。
一般实时流处理的场景中,事件时间可以基本与处理时间保持同步,只是略微有一点延迟,同时保证了窗口计算的正确性。
什么是水位线?
在事件时间语义下,我们不依赖系统时间,而是基于数据自带的时间戳去定义了一个时钟,用来表示当前时间的进展。于是每个并行子任务都会有一个自己的逻辑时钟,它的前进是靠数据的时间戳来驱动的。
分布式系统下遇到的问题:
- 遇到窗口聚合操作时,要攒一批数据才会输出一个结果,所以时间进度的控制不够精细
- 数据向下游任务传递时,一般只能传输给一个子任务,这样其他的并行子任务的时钟就无法推进了
一种简单的解决方法是,在数据流中加入一个时钟标记,记录当前的事件时间;这个标记可以直接广播到下游,当下游任务收到这个标记,就可以更新自己的时钟了。由于类似于水流中用来做标志的记号,在 Flink 中,这种用来衡量事件时间(Event Time)进展的标记,就被称作“水位线”(Watermark)。
水位线可以看作一条特殊的数据记录,它是插入到数据流中的一个标记点,主要内容就是一个时间戳,用来指示当前的事件时间。而它插入流中的位置,就应该是在某个数据到来之后,这样就可以从这个数据中提取时间戳,作为当前水位线的时间戳了。
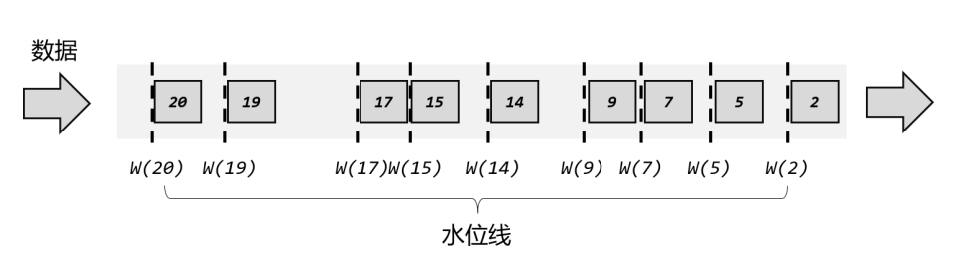
有序流中的水位线
有序流是一种理想状态,数据按照顺序进入流,而且处理的过程中也会保持原先的顺序不变。
每条数据后都插入水位线会导致效率问题:
- 如果当前数据量非常大,可能会有很多数据的时间戳是相同的
- 同时涌来的数据时间差会非常小(比如几毫秒),往往对处理计算也没什么影响
所以为了提高效率,一般会每隔一段时间生成一个水位线,这个水位线的时间戳,就是当前最新数据的时间戳,所以这时的水位线,其实就是有序流中的一个周期性出现的时间标记。

需要注意的是,对于水位线的周期性生成,周期时间是指处理时间(系统时间),而不是事件时间。
无序流中的水位线
在分布式系统中,数据在节点间传输,会因为网络传输延迟的不确定性,导致顺序发生改变,即“乱序数据”。

如果还是和之前一样,靠数据来驱动,每来一个数据就提取它的时间戳、插入一个水位线,那么有可能新的时间戳比之前的还小,直接将这个时间的水位线再插入,“时钟”就回退了,但是水位线代表时钟,时光不能倒流,水位线的时间戳也不能减小。
所以插入新的水位线时,要先判断一下时间戳是否比之前的大,否则就不再生成新的水位线,也就是说,只有数据的时间戳比当前时钟大,才能推动时钟前进,这时才插入水位线。
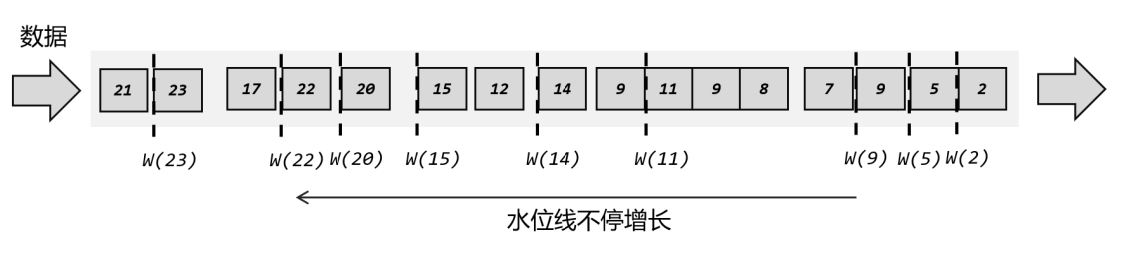
如果考虑到大量数据同时到来的处理效率,同样可以周期性地生成水位线。这时只需要保存一下之前所有数据中的最大时间戳,需要插入水位线时,就直接以它作为时间戳生成新的水位线。

迟到数据的处理
上面的例子中,当 9 秒产生的数据到来之后,我们就直接将时钟推进到了9 秒;如果有一个窗口结束时间就是 9 秒,那么这时窗口就应该关闭、将收集到的所有数据计算输出结果了。
但事实上,由于数据是乱序的,还可能有时间戳为 7 秒、8 秒的数据在 9 秒的数据之后才到来,这就是“迟到数据”(late data)。
回到生产线发货的例子,商品不是按照生产时间顺序到来的,所以有可能 9 点生产的商品已经到了,司机认为已经到了9 点,所以直接发车;但是可能还会有8 点 59 分59 秒生产的商品迟到了,没有赶上这班车。
解决办法就是稍微等一会儿:9 点发车,可以等到 9 点10分,等货物都到齐了再出发。
为了做到形式上仍然是9 点发车,可以更改一下时钟推进的逻辑:当一个货品到达时,不要直接用它的生产时间作为当前时间,而是减上两秒,这就相当于把车上的逻辑时钟调慢了(把司机手上的表调慢两秒)。
回到上面的例子,为了让窗口能够正确收集到迟到的数据,也可以等上2 秒;也就是用当前已有数据的最大时间戳减去 2 秒,就是要插入的水位线的时间戳,这样的话,9 秒的数据到来之后,事件时钟不会直接推进到 9 秒,而是进展到了7 秒;必须等到11 秒的数据到来之后,事件时钟才会进展到 9 秒,这时迟到数据也都已收集齐,0~9 秒的窗口就可以正确计算结果了。

这里等待两秒是依据我们的经验,未必能处理所有的乱序数据。
解决方法是可以试着再多等几秒,也就是把时钟调得更慢一些。最终的目的,就是要让窗口能够把所有迟到数据都收进来,得到正确的计算结果。
对应到水位线上,其实就是要保证,当前时间已经进展到了这个时间戳,在这之后不可能再有迟到数据来了。
水位线的特性
水位线就代表了当前的事件时间时钟,而且可以在数据的时间戳基础上加一些延迟来保证不丢数据,这一点对于乱序流的正确处理非常重要。
- 水位线是插入到数据流中的一个标记,可以认为是一个特殊的数据
- 水位线主要的内容是一个时间戳,用来表示当前事件时间的进展
- 水位线是基于数据的时间戳生成的
- 水位线的时间戳必须单调递增,以确保任务的事件时间时钟一直向前推进
- 水位线可以通过设置延迟,来保证正确处理乱序数据
- 一个水位线Watermark(t),表示在当前流中事件时间已经达到了时间戳 t, 这代表t 之前的所有数据都到齐了,之后流中不会出现时间戳 t’ ≤ t 的数据
如何生成水位线
水位线是用来保证窗口处理结果的正确性的,如果不能正确处理所有乱序数据,可以尝试调大延迟的时间,但是具体应该怎么生成水位呢?
对于水位线,只能尽量取保证正确,想保证正确性只能等,由于网络传输延迟的不确定,为了获取所有迟到的数据,只能等待更长时间。
具体等多长时间,需要我们对相关领域有一定的了解,比如我们知道当前业务中事件迟到的时间不会超过 5 秒,那就把水位线的时间戳设为当前已有数据的最大时间戳减去5 秒,相当于设置了 5 秒的延迟等待。
如果我们希望计算结果能更加准确,那可以将水位线的延迟设置得更高一些,等待的时间越长,自然也就越不容易漏掉数据。不过这样做的代价是处理的实时性降低了,我们可能为极少数的迟到数据增加了很多不必要的延迟。
如果我们希望处理得更快、实时性更强,那么可以将水位线延迟设得低一些。这种情况下,可能很多迟到数据会在水位线之后才到达,就会导致窗口遗漏数据,计算结果不准确。对于这些 “漏网之鱼”。当然,如果对准确性完全不考虑、一味地追求处理速度,可以直接使用处理时间语义,这在理论上可以得到最低的延迟。
Flink 中的水位线,其实是流处理中对低延迟和结果正确性的一个权衡机制,而且把控制的权力交给了程序员。
水位线的传递
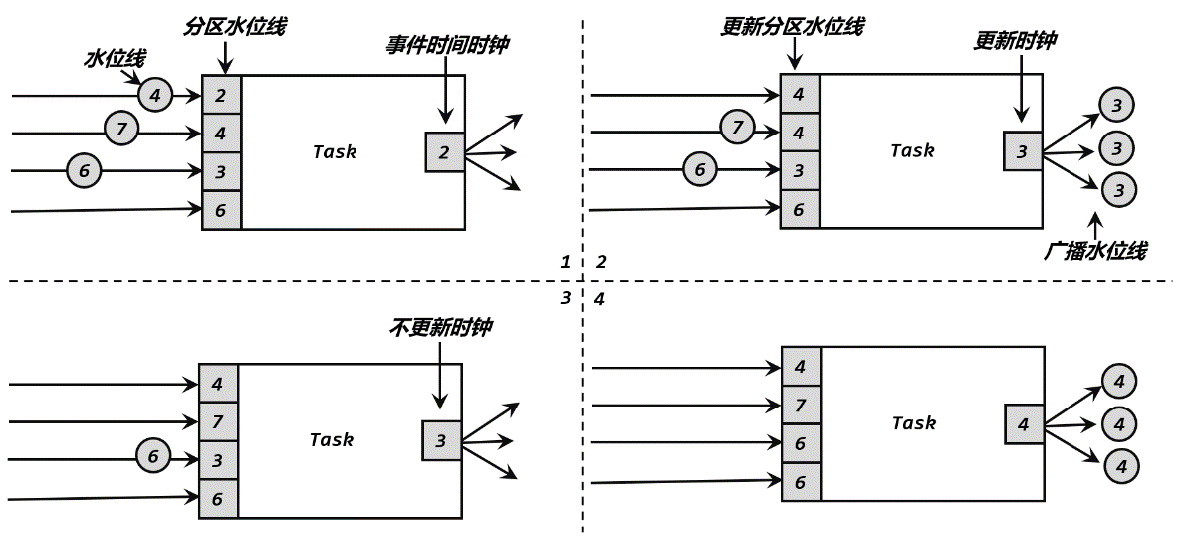
直通式传输:数据和水位线都是按照本身的顺序依次传递、依次处理的,一旦水位线到达了算子任务, 那么这个任务就会将它内部的时钟设为这个水位线的时间戳。
广播式传输:下游有多个并行子任务,那么上游任务处理完水位线,时钟改变之后,要把当前的水位线再次发出,广播给所有的下游子任务。
重分区传输:
水位线定义的本质:它表示的是“当前时间之前的数据,都已经到齐了”。
如果一个任务收到了来自上游并行任务的不同的水位线,说明上游各个分区处理得有快有慢,这时我们要以“这之前的数据全部到齐”为标准(木桶原理?)。
水位线的总结
- 水位线在事件时间的世界里面,承担了时钟的角色
- 水位线是一种特殊的事件,由程序员通过编程插入的数据流里面,然后跟随数据流向下游流动
- 不同的算子看到的水位线的大小可能是不一样的(下游的算子可能并未接收到来自上游算子的水位线,导致下游算子的时钟要落后于上游算子的时钟)
水位线的重要性在于它的逻辑时钟特性,而逻辑时钟这个概念可以说是分布式系统里面最为重要的概念之一了,理解水位线对理解各种分布式系统非常有帮助。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!